Digital Asset Disaster Recovery Explained for IT Leaders

Digital asset disaster recovery is the set of strategies, architectures, and processes an organization uses to protect and restore critical digital assets after a disruptive incident. The industry term for this discipline is operational resilience for digital assets, and it spans everything from cryptographic key management to regulatory reporting timelines. 94% of 2026 digital asset losses traced back to just seven major exploits linked to misconfigured policies, which means most catastrophic losses are preventable with the right architecture in place. Frameworks like DORA and MiCA now mandate formal recovery plans, making this a board-level obligation rather than an IT side project. Understanding digital asset disaster recovery explained in full requires covering architecture, compliance, and live testing together.
What is digital asset disaster recovery?
Digital asset disaster recovery is the formal discipline of designing systems and procedures that guarantee an organization can restore access to, and control of, its digital assets following any disruptive event. Those events include ransomware attacks, exchange failures, smart contract exploits, natural disasters affecting data centers, and the death or incapacitation of key personnel. Unlike traditional IT disaster recovery, which focuses on restoring servers and databases, digital asset recovery centers on cryptographic key availability, wallet policy continuity, and on-chain transaction integrity.
The scope is broader than most IT leaders initially assume. A recovery plan must address private key reconstruction, multi-party signing quorums, custody provider failover, and the chain of custody documentation that regulators now require. Without that scope, a technically functional recovery still fails a compliance audit. This is why organizations treating digital asset recovery as a subset of general IT backup are consistently underprepared when incidents occur.

Recovery architectures: hot, warm, and cold standby
The three foundational configurations in disaster recovery for digital assets map directly to recovery speed and operational cost. Hot standby nodes enable near-zero-downtime failover in seconds. Warm standby recovery takes 5 to 15 minutes. Cold standby restoration requires 30 to 60 minutes. Each tier represents a different trade-off between infrastructure cost and recovery time objective (RTO).
Choosing the right standby tier
Hot standby is appropriate for trading desks, payment processors, and any operation where minutes of downtime translate to direct financial loss. Warm standby suits treasury operations and custody providers where a brief interruption is tolerable but hours of downtime are not. Cold standby works for long-term asset storage where access is infrequent and cost efficiency outweighs speed.
Key security architecture runs parallel to standby configuration. Multisig wallet adoption among high-value Bitcoin addresses grew 147% from 2024 to 2026, reflecting the industry’s shift toward distributed trust models. Multi-party computation (MPC) wallets go further by eliminating the single private key entirely, replacing it with threshold signatures computed across multiple hardware enclaves. Hardware wallets from providers like Ledger and Trezor serve as offline signing devices within these architectures, reducing exposure to network-based attacks.
Backup strategy follows the 3-2-1 rule: three copies of recovery data, on two different media types, with one copy stored off-site. For digital assets, this translates to encrypted key shares stored on hardware security modules (HSMs), fireproof metal backups like Cryptosteel or Bilodeau plates, and geographically distributed vaults. Shamir’s Secret Sharing splits seed phrases into multiple shares so that no single location holds a complete recovery secret, directly mitigating physical disaster risk.
Pro Tip: Never store a complete seed phrase in a single location, even in a fireproof safe. Split it using Shamir’s Secret Sharing across at least three custodians or locations, and document the reconstruction procedure in your recovery runbook.
How do DORA and MiCA affect recovery planning?
Regulatory requirements now define the minimum standard for digital asset recovery planning across European financial markets. DORA and MiCA require initial incident reporting within 4 hours, an intermediate report within 72 hours, and a final report within one month. These timelines are not aspirational targets. They are legal obligations with enforcement consequences for firms operating under EU jurisdiction.
The compliance requirements extend well beyond documentation. Regulators expect organizations to demonstrate continuous operational resilience, meaning the recovery plan must be tested, evidenced, and updated on a defined cadence. A written plan sitting in a SharePoint folder does not satisfy a DORA audit. What satisfies regulators is streaming audit logs to SIEM systems, which creates a continuous, tamper-evident record of recovery operations and test outcomes.
The practical implications for IT teams are significant:
- Maintain a SIEM integration that captures every signing event, failover trigger, and key rotation activity in real time.
- Schedule quarterly live failover drills and document outcomes with timestamped evidence packages.
- Obtain senior management sign-off on the recovery plan annually, and after every material change to the architecture.
- Align drill cadence with regulatory reporting cycles so evidence is always current when an audit request arrives.
- Map each recovery procedure to the specific DORA or MiCA article it satisfies, creating a traceable compliance matrix.
Compliance readiness for 2026 requires treating recovery evidence as a product feature rather than an administrative task. Organizations that automate evidence collection spend significantly less time preparing for audits and significantly more time improving actual recovery capability.
What are the biggest challenges in protecting digital assets?
Single-object failure is the most common and most preventable risk in digital asset protection strategies. When one person holds the only copy of a seed phrase, one fire, one theft, or one death makes the assets permanently inaccessible. Over $200 billion in crypto assets remain permanently inaccessible due to the death of holders who left no recovery documentation. That figure represents a systemic failure of inheritance planning at scale.
Inheritance and succession planning belongs in every enterprise recovery plan. The plan must specify who holds recovery shares, under what legal conditions those shares can be combined, and which legal counsel or trustee has authority to initiate reconstruction. Without this, even a technically sound multisig setup becomes a legal dispute when a key holder dies or becomes incapacitated.
NFT custody introduces recovery complexity that goes beyond key restoration. Institutional NFT disaster recovery requires backing up policy definitions, contract addresses, and metadata pointers, not just private keys. An NFT whose metadata pointer resolves to a deleted IPFS node is functionally worthless even if the private key is intact. Recovery plans for NFT portfolios must include off-chain metadata archiving and registry backup procedures.
“The shift from seed phrases to policy-enforced MPC and hardware-enclave techniques represents the most significant architectural change in digital asset security in a decade. Organizations still relying on single-key custody are operating with infrastructure that regulators and institutional counterparties will no longer accept.”
Geographic redundancy and signer diversity address multi-jurisdictional risk. A multisig quorum where all signers are in the same city is vulnerable to a single regional disaster. Best practice distributes signers across at least three jurisdictions, with no single jurisdiction holding a controlling share. This applies to both human signers and the HSMs or hardware wallets they operate.
Pro Tip: Map every single point of failure in your current custody architecture before designing your recovery plan. A simple dependency diagram often reveals that three or four people share the same office, the same cloud provider, and the same hardware vendor. Diversity across all three dimensions is what creates genuine resilience.
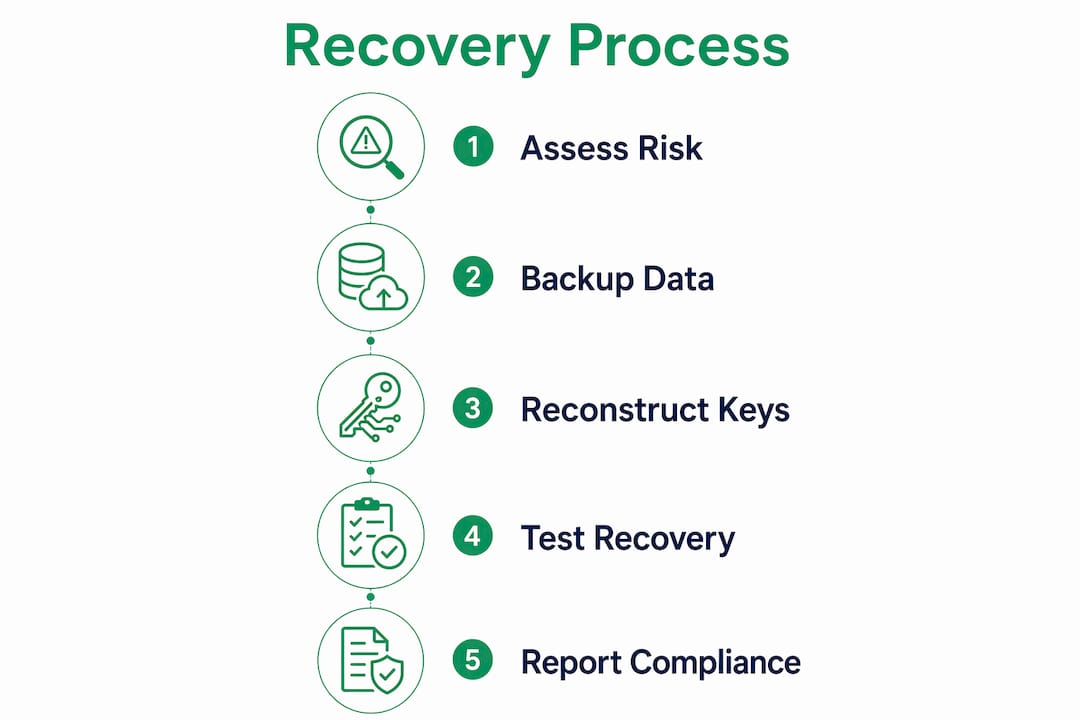
How to implement and test your recovery process
A recovery plan that has never been tested is a hypothesis, not a plan. Regulators require recovery plans signed by senior management with live failover testing and board-approved operational resilience evidence. Tabletop exercises alone are insufficient. The plan must be validated through actual system failover under realistic conditions.
Follow this sequence to build a testable recovery process:
- Define and document RTO components. Architectural RTO is composed of multi-party reconstruction time, attestation latency, infrastructure failover time, and manual coordination overhead. Measure each component separately during initial testing to identify where delays actually occur.
- Draft the recovery runbook. The runbook specifies every step, every responsible party, every tool, and every decision point in the recovery sequence. It must be written at a level of detail that allows a qualified substitute to execute it without prior context.
- Conduct a break-glass test. Simulate a complete loss of primary signing infrastructure and measure actual recovery time against the documented RTO. Record every deviation and update the runbook accordingly.
- Integrate with compliance evidence packaging. Every test generates timestamped logs, screenshots, and sign-off records. Package these as evidence artifacts and store them in your audit repository.
- Rotate keys after every test. Key rotation after a drill confirms that the rotation procedure itself works and reduces the risk that test credentials are ever used in a production incident.
The following table maps recovery architecture tiers to their key testing parameters:
| Architecture tier | Target RTO | Test frequency | Evidence artifact |
|---|---|---|---|
| Hot standby | Under 60 seconds | Monthly | Automated failover log |
| Warm standby | 5 to 15 minutes | Quarterly | Manual drill report |
| Cold standby | 30 to 60 minutes | Semi-annually | Full reconstruction record |
Board-level oversight of recovery testing is not optional under DORA. The board must receive evidence that recovery capabilities meet documented RTOs, and that evidence must be current at the time of any regulatory examination.
Key takeaways
Effective digital asset disaster recovery requires distributed key architecture, continuous compliance evidence, and live failover testing validated at board level.
| Point | Details |
|---|---|
| Architecture determines RTO | Hot standby recovers in seconds; cold standby takes up to 60 minutes. Match the tier to your operational tolerance. |
| Multisig and MPC reduce single-point risk | Distributed signing across hardware enclaves and geographic locations eliminates the single-key failure mode. |
| DORA and MiCA set hard reporting deadlines | Initial incident reports are due within 4 hours. Written plans without live test evidence do not satisfy regulators. |
| Inheritance planning prevents permanent loss | Over $200 billion in assets are inaccessible due to missing succession documentation. Every recovery plan needs a legal succession clause. |
| Live testing is the compliance standard | Tabletop exercises are insufficient. Regulators require actual failover tests with senior management approval and timestamped evidence. |
Why most recovery plans fail before they are ever needed
Most digital asset recovery plans fail for the same reason most insurance policies go unclaimed: they were written once, filed, and never touched again. I have reviewed recovery documentation from organizations that had invested heavily in multisig infrastructure and MPC wallets, only to discover that the runbook referenced personnel who had left the company, HSMs that had been decommissioned, and a SIEM integration that had never actually been configured. The architecture was sound. The documentation was fiction.
The organizations that get this right treat recovery as an operational discipline, not a compliance checkbox. They run quarterly drills the same way a trading desk runs stress tests. They rotate keys on a schedule, not in response to incidents. They assign a named owner to every recovery dependency and review that ownership list every time someone changes roles.
The regulatory shift toward continuous evidence is the most important development in this space. DORA and MiCA are not asking for better documentation. They are asking for proof that the system actually works, on demand. That is a fundamentally different standard, and it requires a fundamentally different organizational posture. The firms that will pass regulatory scrutiny in 2027 and beyond are the ones building automated recovery verification into their operations today, not the ones writing longer plans.
Cross-disciplinary collaboration is the other factor that separates functional recovery programs from theoretical ones. Legal, treasury, information security, and operations must all contribute to the recovery plan and all participate in drills. A technically perfect failover that violates a custody agreement or triggers an unreported regulatory incident is not a successful recovery. It is a different kind of failure.
— Gregg
How DARE supports your digital asset recovery readiness
If your organization is building or auditing its recovery posture, Wush’s Digital Asset Readiness Evaluation (DARE) provides the structured framework to close the gaps. DARE covers custody architecture, regulatory compliance, operational controls, and recovery testing evidence in a single certification program designed for finance professionals, risk managers, and IT security teams.
The DARE certification includes modular assessments mapped directly to DORA, MiCA, and institutional custody standards, so your team builds recovery capability and compliance evidence simultaneously. Annual renewal keeps your credentials current as regulations evolve. Explore the DARE certification program to see how your organization’s recovery readiness measures against the standard, or visit dare.wush.co to review the full framework.
FAQ
What is digital asset disaster recovery?
Digital asset disaster recovery is the set of processes and architectures that protect and restore an organization’s digital assets after a disruptive event. It covers cryptographic key management, wallet policy continuity, custody failover, and regulatory incident reporting.
How long does digital asset recovery take?
Recovery time depends on the standby architecture in use. Hot standby systems recover in seconds, warm standby takes 5 to 15 minutes, and cold standby restoration requires 30 to 60 minutes under standard conditions.
What do DORA and MiCA require for incident reporting?
DORA and MiCA require an initial incident report within 4 hours, an intermediate report within 72 hours, and a final report within one month of the incident occurring.
Is a written recovery plan enough to satisfy regulators?
No. Regulators require live failover testing with timestamped evidence and senior management approval. Streaming audit logs to a SIEM system provides the continuous operational resilience evidence that satisfies regulatory expectations beyond static documentation.
What is the biggest risk in self-custody digital asset recovery?
Single-object failure is the primary risk. When one person or one location holds the only recovery credential, any single point of failure makes assets permanently inaccessible. Multisig wallets and Shamir’s Secret Sharing directly mitigate this by distributing trust across multiple parties and locations.